

 分类:
Java集合
分类:
Java集合
一、哈希表
JDK8之前,底层采用数组+链表实现。
JDK8以后,底层进行了优化。由数组+链表+红黑树实现。
二、HashSet1.7版本原理解析
当要将元素存入HashSet时
1.创建时默认长度16,默认加载因子0.75的数组,数组名table
加载因子的作用:当数组里面存了16*0.75 = 12个元素的时候,数组就会扩容为原先的两倍
2.根据元素的哈希值跟数组的长度计算出应存入的位置
3.判断当前位置是否为null,如果是null直接存入
4.如果应存入的位置不为null,表示有元素,则调用equals方法比较属性值
5.如果一样,则不存,如果不一样,则存入数组,老元素挂在新元素下面
样式如下图:
红色编号为元素添加的顺序,颜色相近(5至6)的为计算插入的位置相同,颜色相同(3和6)的为属性值也相同的
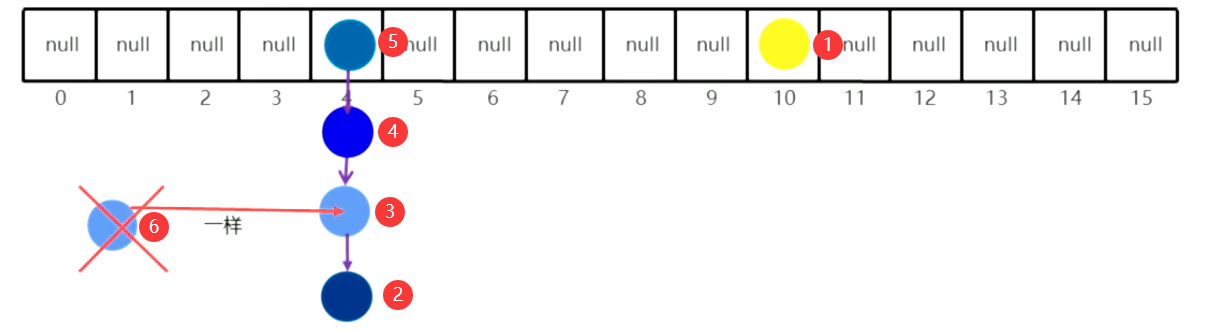
HashSet1.7版本原理总结
底层结构:哈希表。(数组+链表)数组的长度默认为16,加载因子为0.75
首先会先获取元素的哈希值,计算出在数组中应存入的索引
判断该索引处是否为null
如果是null,直接添加
如果不是null,则与链表中所有的元素,通过equals方法比较属性值
只要有一个相同,就不存,如果都不一样,才会存入集合。
三、HashSet1.8版本原理解析
底层结构∶哈希表。(数组、链表、红黑树的结合体)。
当挂在下面的元素过多,那么不利于添加,也不利于查询,所以在JDK8以后,当链表长度超过8的时候,自动转换为红黑树。但是存储流程不变。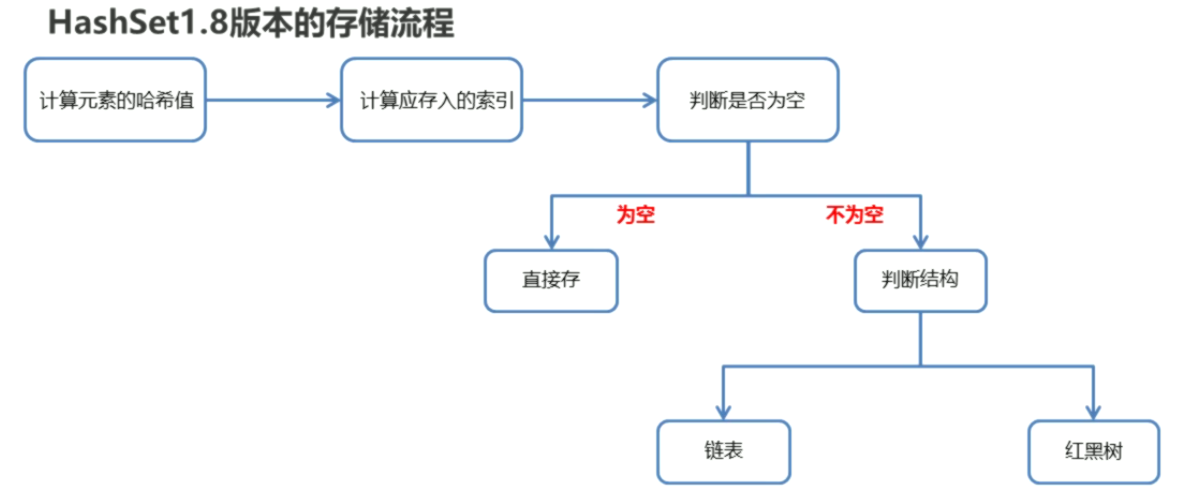
案例:HashSet集合存储学生对象并遍历
需求∶创建一个HashSet集合,存储多个学生对象,并进行遍历
要求:学生对象的成员变量值相同,我们就认为是同一个对象
思路∶
①定义学生类
注意:没有重写hashCode方法,是根据对象的地址值计算的哈希值。如果不重写那么学生对象的成员变量值相同也会被存入。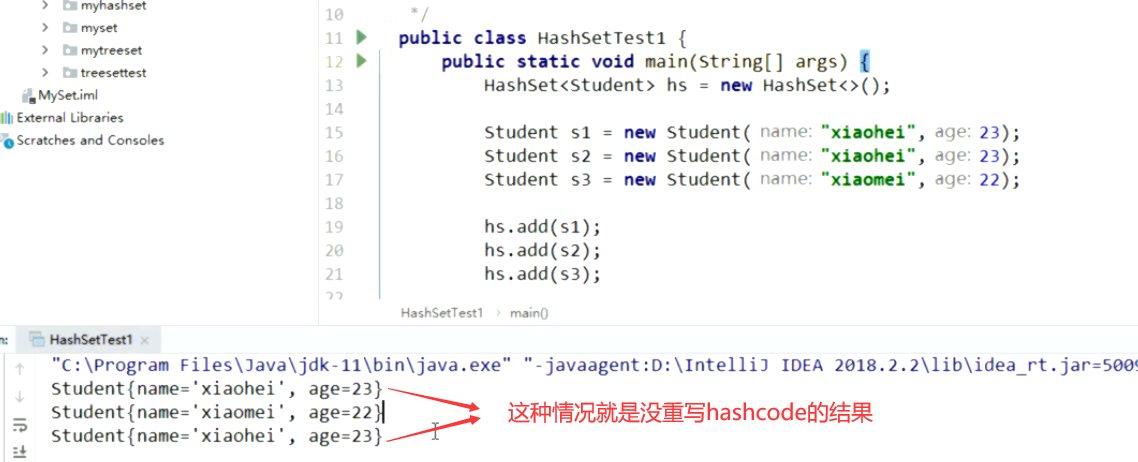
②创建HashSet集合对象



 50010702506256
50010702506256
