

排名
6
文章
6
粉丝
16
评论
8
{{item.articleTitle}}
{{item.blogName}} : {{item.content}}
ICP备案 :渝ICP备18016597号-1
网站信息:2018-2026TNBLOG.NET
技术交流:群号656732739
联系我们:contact@tnblog.net
公网安备: 50010702506256
50010702506256
50010702506256

欢迎加群交流技术

 分类:
.NET
分类:
.NET
例如字符串 : net core使用EF之DB First
拆分后应该为:net core ,使用,EF,之,DB First
方法1:先找到字符串中的中文,然后根据中文在循环拆分字符串
string key = "net core使用EF之DB First";
//先找到所有的中文
List<string> chs = new List<string>();
Regex reg = new Regex("[\u4e00-\u9fa5]+");
foreach (Match v in reg.Matches(key))
chs.Add(v.Value);
//然后根据中文来截取
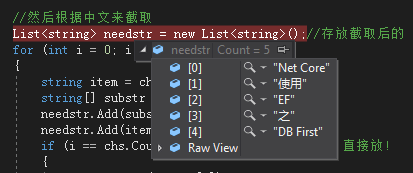
List<string> needstr = new List<string>();//存放截取后的
for (int i = 0; i < chs.Count(); i++)
{
string item = chs[i];
string[] substr = key.Split(item);
if (!string.IsNullOrWhiteSpace(substr[0]))
{
needstr.Add(substr[0]);//存放一下前半部分
}
needstr.Add(item);//存放一下自己
if (i == chs.Count - 1)//已经是最后一次了,直接放!
{
if (!string.IsNullOrWhiteSpace(substr[1]))
{
needstr.Add(substr[1]);
}
}
else
{
key = substr[1];//把需要截取的变成后半部分,以便于用于在下一次截取
}
}效果如下:
方法2:先找到字符串中的中文所在的位置,然后在根据中文位置循环拆分字符串
string key = "net core使用EF之DB First";
//先找到中文所在的位置
List<int> chpois = new List<int>();
char[] testbyte = key.ToArray();
for (int i = 0; i < testbyte.Length; i++)
{
//找到中文所在的位置
if (testbyte[i] >= 0x4E00 && testbyte[i] <= 0x9FA5)
{
chpois.Add(i);
}
}
//开始截取
//.............欢迎加群讨论技术,1群:677373950(满了,可以加,但通过不了),2群:656732739。有需要软件开发,或者学习软件技术的朋友可以和我联系~(Q:815170684)
评价