

 分类:
微服务
分类:
微服务
本篇文章翻译自:https://www.consul.io/docs/architecture
Consul 架构
Consul是一个复杂的系统,它有许多不同的活动部件。为了帮助Consul的用户和开发人员形成一个关于它如何工作的思维模型,本页介绍下Consul系统架构。
在描述架构之前,我们建议阅读术语表,以帮助大家更好的了解讨论的内容。
在生产中部署Consul时,本文档中的架构概念可以与参考架构指南一起使用。
整体架构
从宏观角度看, Consul架构是这样的。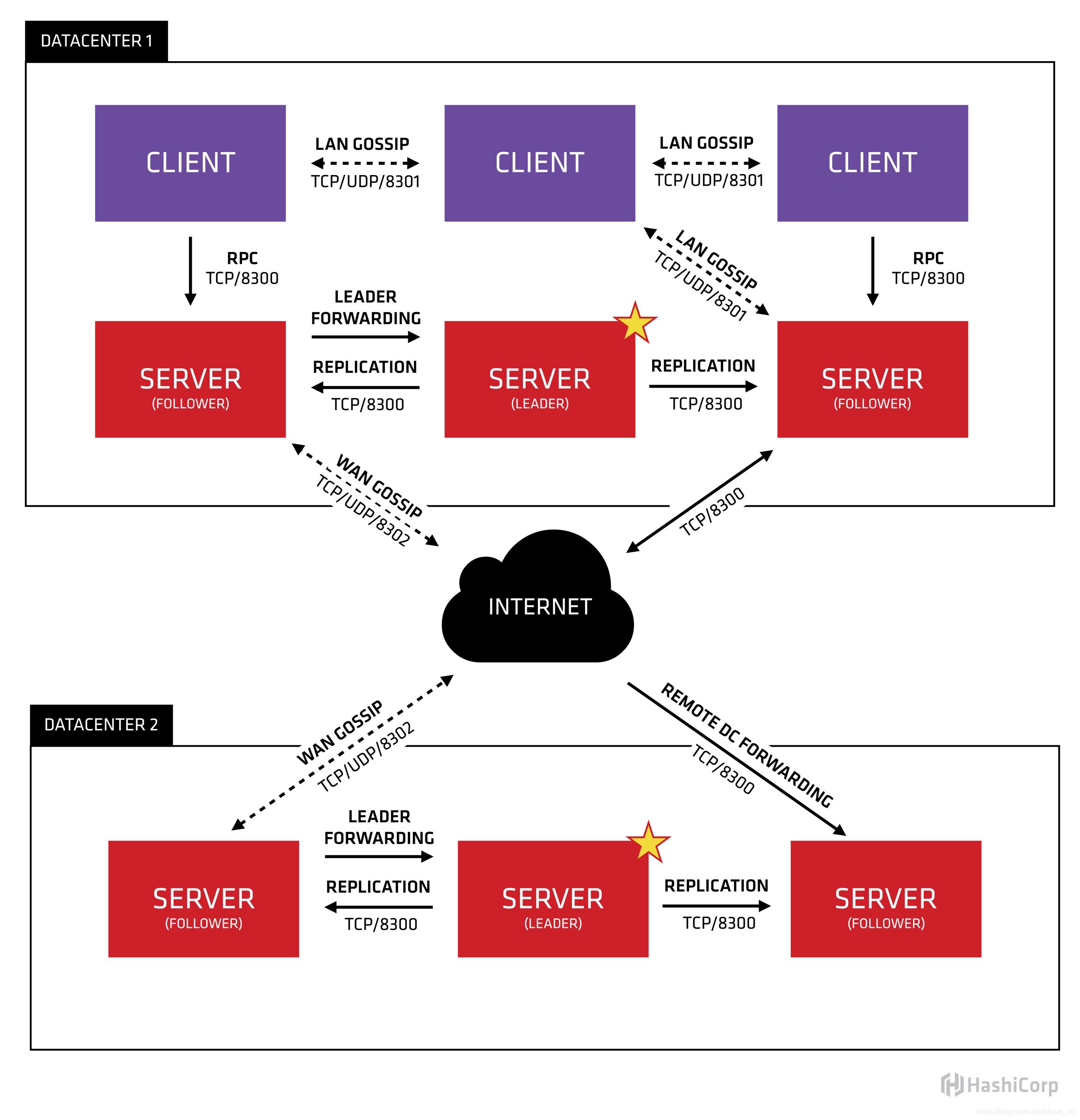
我们来分析一下这张图,并描述一下每一个部分。首先,我们可以看到有两个数据中心,分别标注为 "DATACENTER1"和 “DATACENTER2”。Consul对多个数据中心有天然非常好的支持,并希望这是常见的情况。
在每个数据中心内,我们有Client和Server的混合。预计会有3到5台Server。这是在权衡故障场景下可用性和性能之间取得平衡的结果,因为随着机器的增加,共识的速度会逐渐变慢。然而,Client的数量没有限制,它们可以轻松地扩展到数千或数万。
所有在数据中心的代理都会参与一个Gossip协议。这意味着有一个Gossip池,其中包含了某个数据中心的所有Agent。这有几个目的:
第一,客户端不需要配置Server的地址,发现工作是自动完成的。
第二,检测代理故障的工作不放在Server上,而是分布式的。这使得故障检测的扩展性比原生的心跳方案要强得多。同时,它还为节点提供了故障检测,如果代理无法到达,那么该节点可能已经发生了故障。
第三,它被用作消息层,当发生重要事件(如Leader 选举)时进行通知。
每个数据中心的Server都是单一Raft对等集的一部分。这意味着它们共同选出一个单一的Leader,一个被选中的Server,它有额外的职责。Leader负责处理所有查询和事务。事务也必须复制到所有参与共识协议的分片。由于这一要求,当None-Leader Server收到RPC请求时,它会将其转发给集群Leader。
Server Agent还作为WAN(广域网) Gossip Pool的一部分进行操作。这个池子与**LAN(局域网)**池不同,因为它是针对互联网的较高延迟进行优化的,WAN池只包含其他Consul 数据中心的Sever Agent。这个池的目的是让数据中心以低接触的方式发现彼此。让一个新的数据中心上线就像加入现有的WAN Gossip 池一样简单。因为服务器都在这个池中运行,所以还可以实现跨数据中心的请求。当一台Server收到一个不同数据中心的请求时,它会将其转发到正确数据中心的随机Server。然后该Servevr可能会转发到本地Leader。
这导致数据中心之间的耦合度很低,但由于故障检测、连接缓存和多路复用,跨数据中心的请求相对快速可靠。
一般情况下,不同的Consul数据中心之间不会复制数据。当对另一个数据中心的资源进行请求时,本地Consul服务器会将该资源的RPC请求转发给远程Consul服务器,并返回结果。如果远程数据中心不可用,那么这些资源也将不可用,但这不会以其他方式影响本地数据中心。
在一些特殊情况下,可以复制有限的数据子集,比如使用Consul内置的ACL复制功能,或者使用consul-replicate等外部工具。 在某些地方,Client Agent可能会从Server上缓存数据,使其在本地可用,以提高性能和可靠性。例如, 包括连接证书和它允许Client代理对入站连接请求做出本地决定,而无需往返Server的场景。一些API端点还支持可选的结果缓存。这有助于可靠性,因为即使与服务器的连接中断或服务器暂时不可用,本地Agent仍然可以继续从缓存中响应一些查询,如服务发现或Connect授权。
深入了解
在这一点上,我们已经涵盖了Consul的高层架构,但每个子系统还有很多细节。共识协议和Gossip协议一样,都有详细的文档。安全模型和使用的协议的文档也有。
其他细节,可以查阅代码,在IRC中询问,或者联系邮件列表。
参考文档
Consul中文文档:
https://yushuai-w.gitbook.io/consul/
转载:https://blog.csdn.net/shuai_wy/article/details/109287318


 50010702506256
50010702506256
