


 50010702506256
50010702506256


 分类:
Python
分类:
Python
爬虫
爬虫就是一只猪,蜘蛛。。 网络蜘蛛。
互联网是一个网由各个网站组成。无数的蜘蛛就在网上到处爬,根据网址从一个网站爬到另一个网站,把你能看到的所有网站搬回来给你 就就叫爬虫了。
爬虫能做什么呢:
a.我们使用的各大搜索引擎其实就是爬虫,把互联网上的的信息爬回来整理,在你搜索关键字的时候给你展示相关的信息。 比如百度,google之类的
b.你用的各种抢票软件也是爬虫,不停的请求去12306刷新余票 发现有票就帮你下单
c.你可能使用的各种第三方微博app端,也是爬虫 因为微博上各种广告或者杂七杂八的无用信息太多,爬虫把正常的微博数据爬下来用一个新的APP去显示..
d.还有你可能在各种电商平台淘宝京东等使用的各种比价、抢券插件,也是爬虫 他们不辞辛苦的日夜不停的搬着数据 存下来,当你去看什么宝贝的时候 就把他以前的数据价格 给你看
e.还有一些大数据之类的 也是通过爬虫爬来数据 整理分析..
f.还有刷浏览量啊 回复啊 刷投票啊 之类的。。 也能用爬虫做到
有些网站想被爬虫爬 比如你做的网站想要搜索靠前,你就得想法设法的让百度能更好的识别你的网站 这些东西衍生出来了SEO
有些网站不想被爬虫爬 比如12306 为什么12306这么卡..我们手动去点 每秒最多2,3次 而爬虫模拟操作。。 1秒成千上万次,为什么12306的验证码这么奇葩,就是为了防止爬虫,然并卵..
所以我们不能说爬虫好 或者是爬虫不好。。 技术无罪
Java,C#一样能写爬虫,为什么要用python,因为Python最牛的地方在于他有着丰富的第三方库,不用再重复造轮子,相对于JAVA、C#开发效率更高,代码了更少,而且入门编写更简单
只需要一个pip install .. ,然后一个import ...
实例:
我们就来爬一下博客首页的所有文章的信息
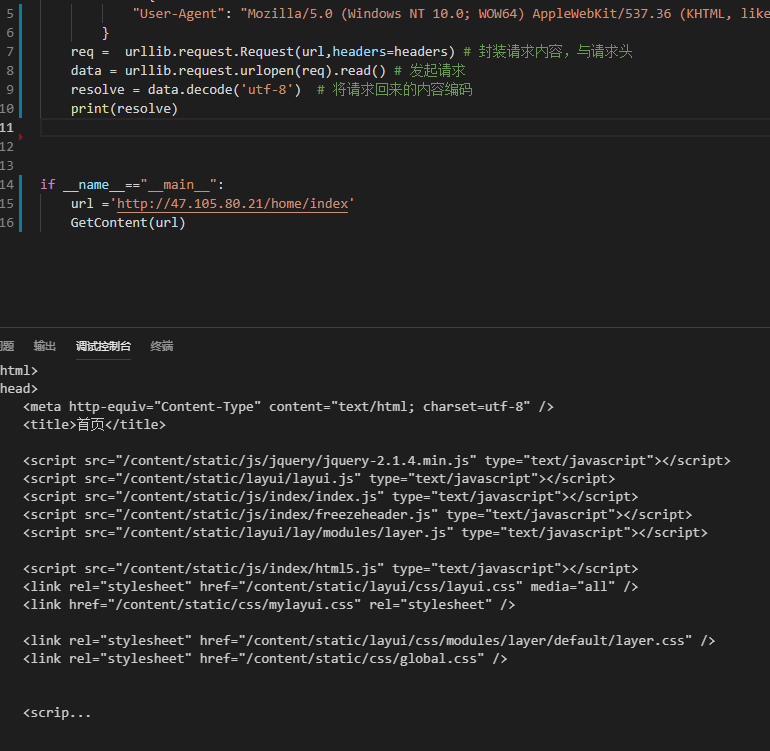
1.先把博客首页爬下来
import urllib.request # 导入内置的爬虫库
def GetContent(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"
}
req = urllib.request.Request(url,headers=headers) # 封装请求内容,与请求头
data = urllib.request.urlopen(req).read() # 发起请求
resolve = data.decode('utf-8') # 将请求回来的内容编码
print(resolve) #获取到的网页源码
if __name__=="__main__":
url ='http://47.105.80.21/home/index'
GetContent(url)爬回来的内容:
然后我们在分析一下网站
可以看到网站的一篇文章就是一个div块 而文章标题和浏览数量 作者信息都包含在里面
我们可以用正则解析出我们想要的内容
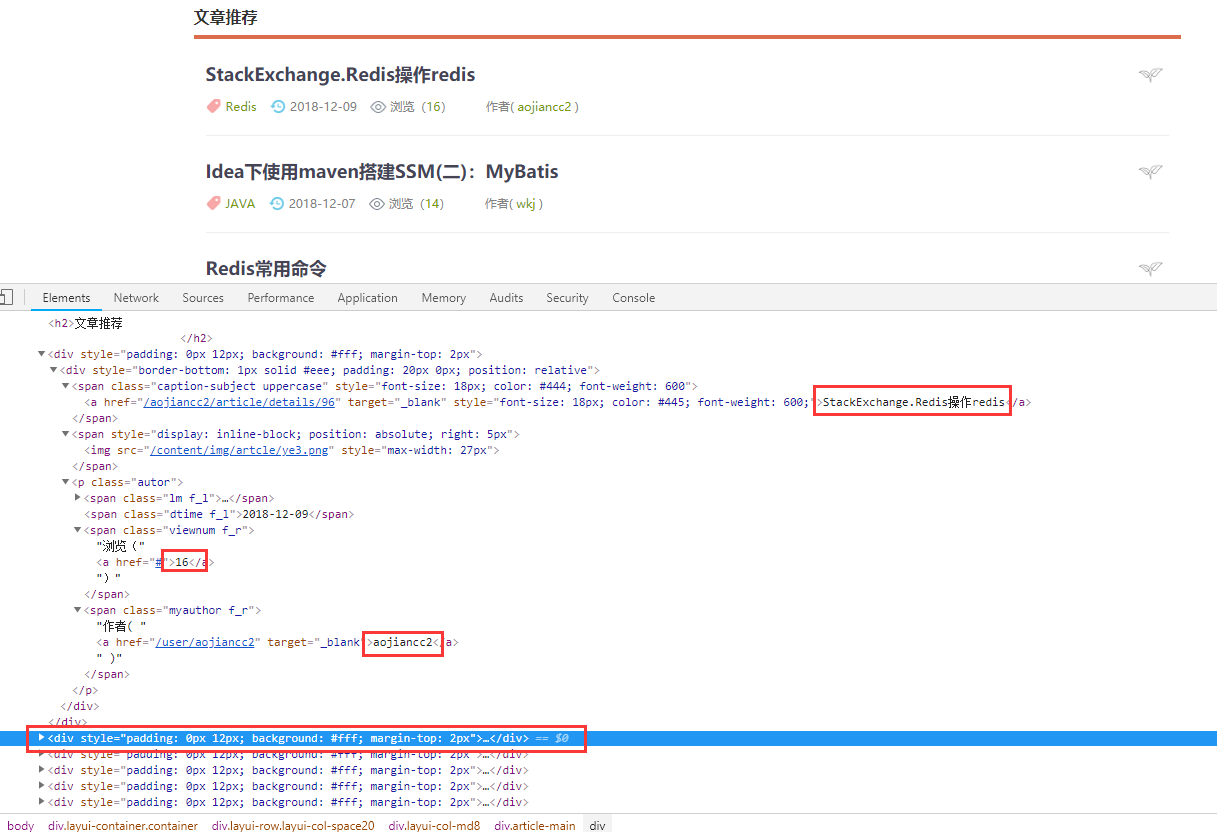
分析之后。。
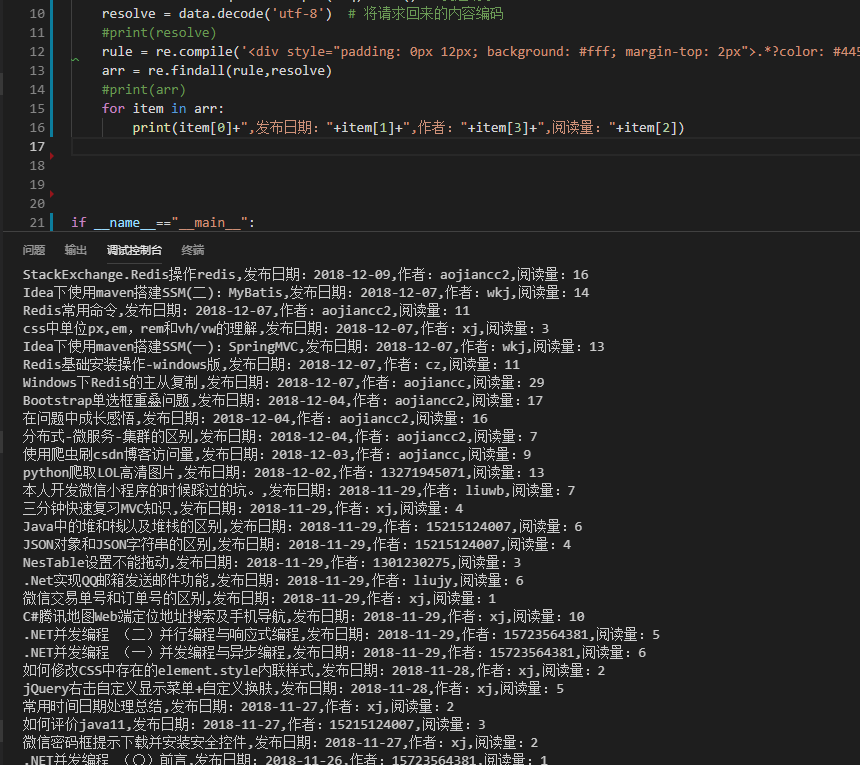
全都出来啦!
代码: 主要是使用了正则来匹配我们需要的内容
import urllib.request # 导入内置的爬虫库
import re # 导入正则库
def GetContent(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"
}
req = urllib.request.Request(url,headers=headers) # 封装请求内容,与请求头
data = urllib.request.urlopen(req).read() # 发起请求
resolve = data.decode('utf-8') # 将请求回来的内容编码
#print(resolve)
rule = re.compile('<div style="padding: 0px 12px; background: #fff; margin-top: 2px">.*?color: #445; font-weight: 600;">(.*?)</a>.*?<span class="dtime f_l">(.*?)</span>.*?<a href="#">(\d+)</a>.*?<a href=".*?" target="_blank">(.*?)</a>',re.S)
arr = re.findall(rule,resolve)
#print(arr)
for item in arr:
print(item[0]+",发布日期:"+item[1]+",作者:"+item[3]+",阅读量:"+item[2])
if __name__=="__main__":
url ='http://47.105.80.21/home/index'
GetContent(url) 正则写得比较渣。。 后面会介绍其他方法来解析我们爬回来的内容,简单强大!!
酱紫
以上
剑哥正在写限制IP频率反爬的功能,等他写好了 咱们来写写使用代理爬取 
欢迎加群讨论技术,1群:677373950(满了,可以加,但通过不了),2群:656732739